
Phylo x Scale Labs: DrugDiscoveryBench proves LLMs are not all you need for drug discovery
Xinming Tu, Member of Technical Staff at Phylo Yuanhao Qu, Co-Founder & President In partnership with Scale Labs
We get one question more than any other: which model is best for drug discovery? Our latest benchmark gave us a clear answer: which LLM you pick matters far less than people think. What you build around it is what gets the work done.
Built with Scale Labs, our latest benchmark DrugDiscoveryBench consists of 82 tasks written by working drug discovery scientists, covering the early stages of the pipeline: finding targets, mining patents, analyzing structure-activity relationships. Every task has a verifiable answer and an expert-written rubric, and the agents solve them by writing code that queries real biomedical databases and tools. All of it runs on an evaluation environment adapted from the open-source version of our open-source Biomni environment (https://github.com/snap-stanford/biomni). You can read the full paper for the complete method and scores at Paper Link, and view the live leaderboard at https://labs.scale.com/leaderboard/drugdiscoverybench.
No single model wins
The top three frontier models land within five points of each other: GPT-5.5 at 51.6%, Gemini 3.5 Flash at 50.0%, Opus 4.8 at 47.2%. But no single one wins everything. Gemini solves the most structural-reasoning tasks, GPT leads on database screening and patent mining, and Opus comes out ahead on target identification and genetics. So instead of standardizing on one model, route each task to whichever handles it best.
Figure 6, DrugDiscoveryBench (Scale Labs and Phylo).
The harness matters as much as the model
A harness is everything around the model: the agent architecture that decides how it calls tools, holds its context, and recovers from errors. A good one gives the LLM a cleaner path to the biological tools, databases, and packages it needs. We held the model fixed and changed only the harness, and the scores moved sharply. GLM 5.2 climbed from 24.4% to 37.8%, and GPT-5.5 from 40.6% to 51.6%. Same model, very different results.
Anthropic's agents in biology research shares the same finding: once they gave agents a deterministic tool for querying biological data, accuracy jumped above 90% and the choice of model mattered much less.
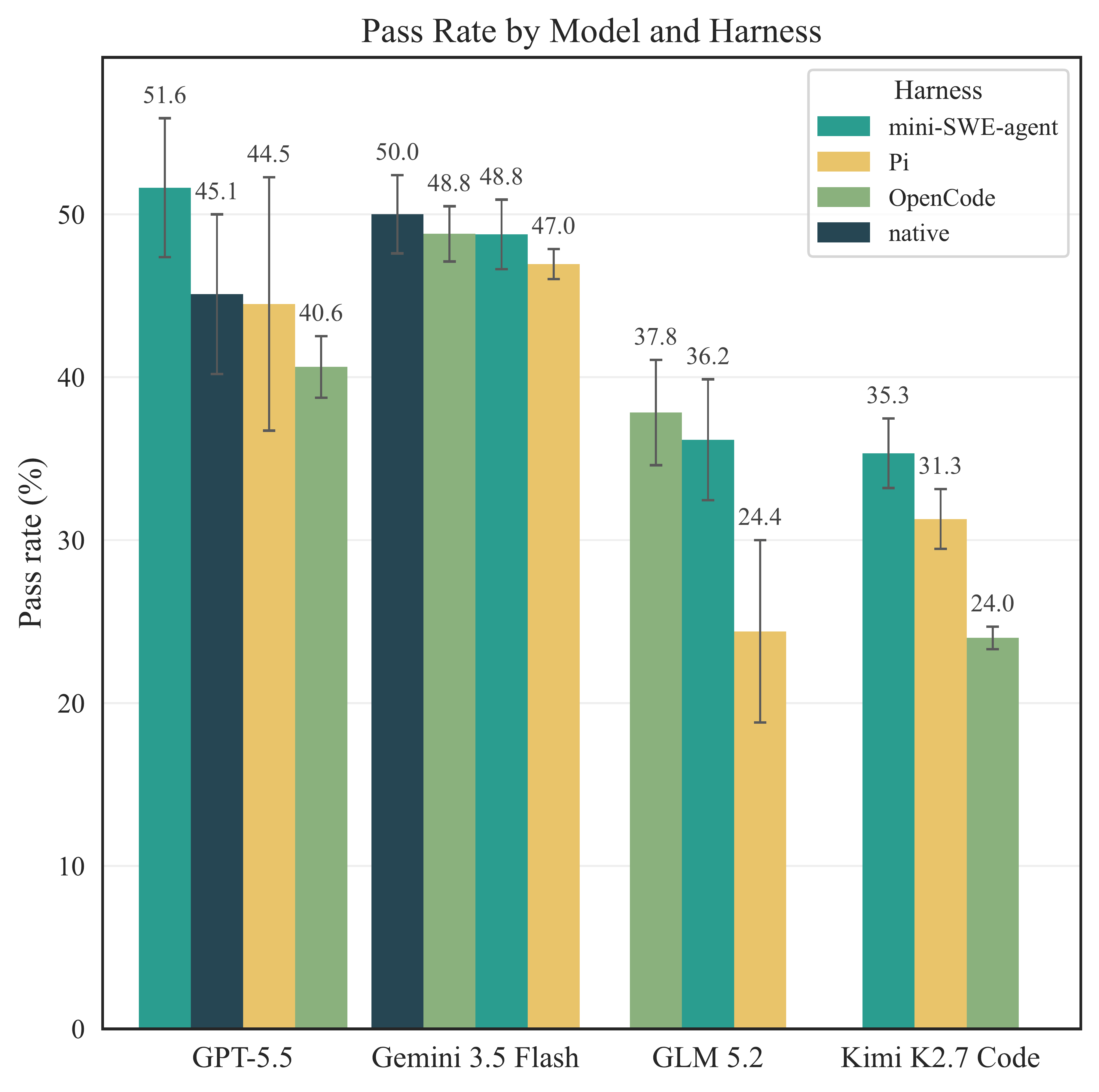
Figure 5, DrugDiscoveryBench (Scale Labs and Phylo).
Your expertise is what closes the gap
On their own, the agents passed only about half the tasks. Handed a human-written playbook, the exact steps to take and which tools to use, at least one model passed 76 of 82, over 90%. The difference is human expertise. Agents handle a single query or calculation fine, but they lose the thread on long workflows: a constraint from the question quietly drops, or the agent solves for the wrong thing and never notices, then hands back a confident, wrong answer. In one task, it answered a melanoma question with a breast-cancer gene, a slip any scientist would catch in seconds.
So your expertise matters more than ever. The judgment, know-how, and common sense you bring are what make an agent reliable. Agents still need a scientist watching the work, and the best thing you can do is capture what you know as procedures an agent can follow.
Biomni Lab: Your Integrated Biology Environment for Drug Discovery
This is why we built Biomni Lab as an integrated, model-agnostic environment for the messy, end-to-end work of real biology research. Biomni Lab collaborates with you, the biologist. It helps capture your expertise and build it into proprietary intelligence that scales and stays yours. Everything sits in one place: hundreds of databases, tools, and packages, specialized biology models, expert skills, and the compute to run them. Because it isn't tied to one model, it routes each task to whichever model is best suited.
This is the new way biologists work.
Try Biomni Lab → https://biomni.phylo.bio