Phylo Brings the NVIDIA BioNeMo Ecosystem into Biomni Lab
By Phylo
Biomni Lab is built around a simple idea: scientists should be able to move from biological questions to computational workflows without stitching together APIs, scripts, models, and databases by hand. NVIDIA BioNeMo is helping make that possible for AI-driven biology.
As NVIDIA launches the BioNeMo Agent Toolkit, we’re excited to share how Biomni Lab is beginning to use the BioNeMo ecosystem across skills, datasets, models, and accelerated workflows.
Why BioNeMo
NVIDIA BioNeMo is an open development platform for AI-driven biology and drug discovery. Unlike the internet-scale corpora that general-purpose language models train on, biology and chemistry lack a comparable mass of open data. To close that gap, NVIDIA partners with leading organizations to build and release high-quality datasets and open models for the field to use freely, under permissive licenses.
How the integration works
In Biomni Lab, we are beginning to integrate BioNeMo ecosystem resources as scientific skills, starting with structure and sequence data from resources such as the AlphaFold Database and synthetic protein scaffold datasets.
These skills are designed to help researchers retrieve predicted structures, evaluate model confidence, identify useful scaffolds, and carry the results into downstream analysis, model training, or design workflows.
We are also integrating open models from the BioNeMo ecosystem where they add new scientific capabilities to Biomni. The first additions include RNAPro for RNA structure prediction and CodonFM for codon-level RNA modeling, followed by protein and small-molecule design models such as La-Proteina, GenMol, and ReaSyn. These models will run as open weights on Biomni’s own accelerated compute backend, alongside the rest of Biomni’s tool ecosystem, so researchers can use them through natural-language scientific workflows rather than standalone scripts.
Examples
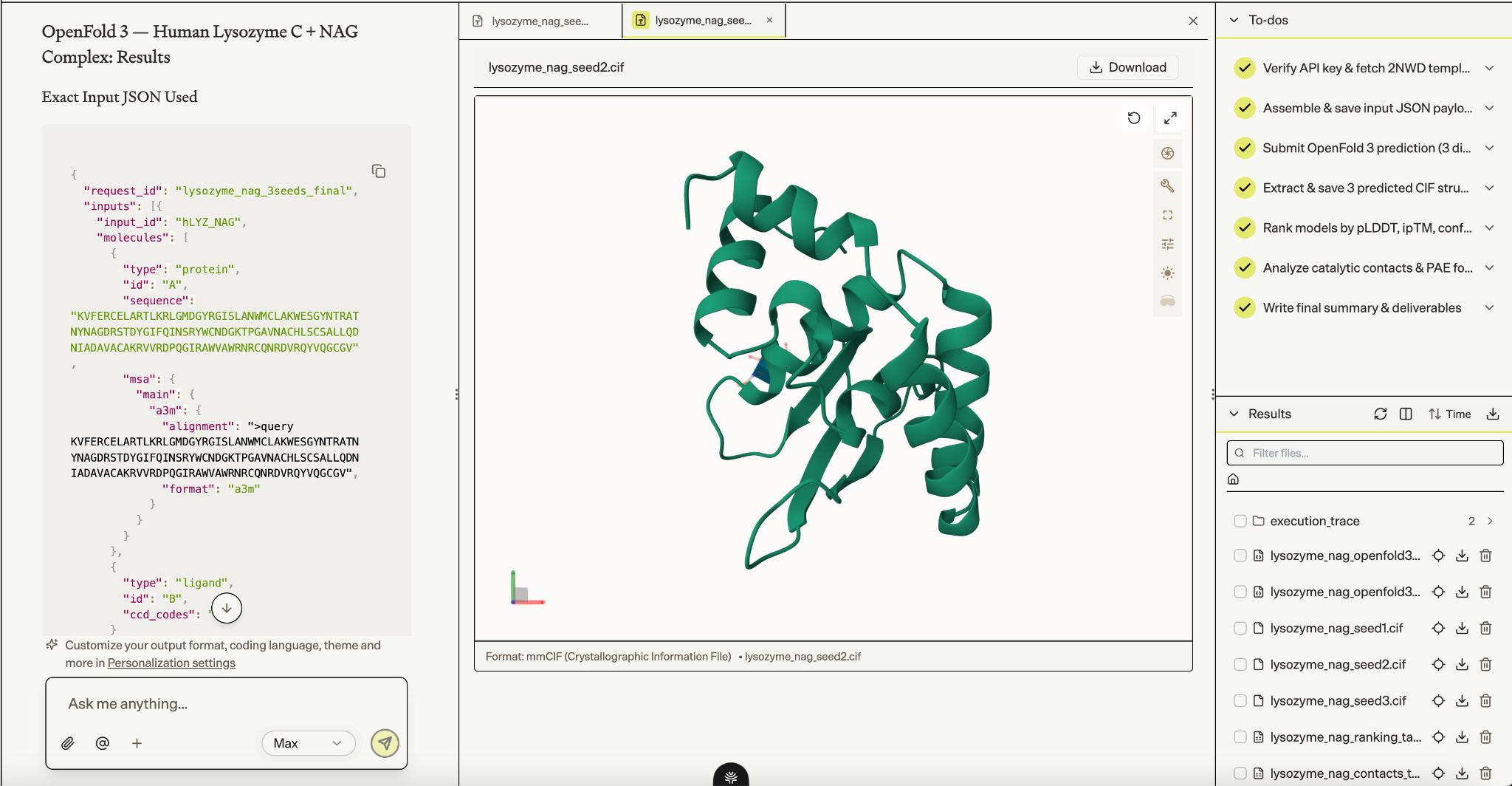
1. Modeling a protein–ligand complex with OpenFold 3
Use OpenFold 3 to predict the structure of human lysozyme C in complex with N-acetyl-D-glucosamine, using three sampled models, and rank the outputs by structure confidence, ligand placement, catalytic-site contacts, and pocket-level uncertainty.
Biomni modeled mature human lysozyme C with NAG in the catalytic cleft, ranked three OpenFold 3 predictions, and analyzed contacts to the catalytic residues Glu35 and Asp53. The top models showed very high protein-fold and pocket confidence, catalytic-site contacts across all three samples, and ligand/interface confidence consistent with NAG being a small substrate fragment, while also surfacing pose and geometry caveats.
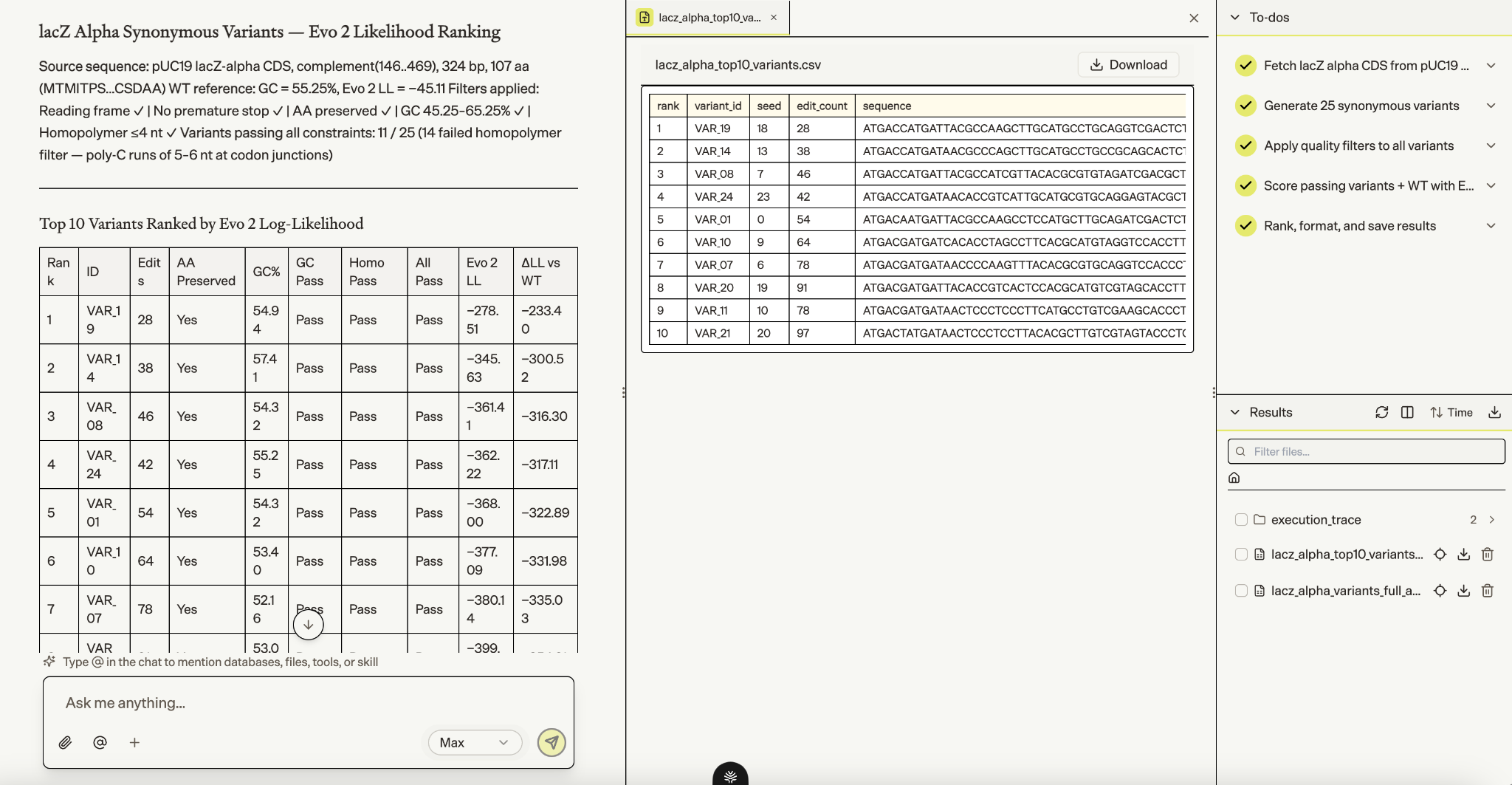
2. Designing synonymous variants with Evo 2
Use Evo 2 to generate synonymous variants of the E. coli lacZ alpha coding sequence that preserve the amino acid sequence while varying codon usage, then filter for reading frame, stop codons, GC content, and homopolymer constraints before ranking variants by model likelihood.
Biomni generated 25 protein-preserving lacZα synonymous variants, filtered them for sequence-design constraints, and scored the passing variants using Evo 2 sequence likelihood. The top 10 variants all preserved the original protein and passed the filters; the native sequence scored highest overall, while the best variants represented the least unnatural synonymous redesigns under Evo 2.
3. Filling the structure gap with AlphaFold
Use the AlphaFold Database API to retrieve the predicted 3D structure of the human protein C19orf12 (UniProt Q9NSK7), which has no experimental structure in the PDB, and report its key metadata along with a summary of the per-residue pLDDT confidence and the PAE matrix.
Biomni identified the canonical AlphaFold model, AF-Q9NSK7-F1, retrieved the structure and confidence files, and summarized whether the prediction was suitable for downstream use. The model had a mean pLDDT of about 60, with the most reliable region around residues 37–57 and high uncertainty in long-range positioning from the PAE matrix.
Get started
1. In Biomni Lab, the BioNeMo datasets are available by API calls.
2. In Biomni Lab, go to Settings → Integrations → Nvidia NIM to paste in a NIM API key.
3. Try one of the prompts above, or bring your own target.